 Overview
Overview
Recently, deep learning with convolutional neural networks (CNNs) and recurrent neural networks (RNNs) has become universal in all-around applications. CNNs are used to support vision recognition and processing, and RNNs are able to recognize time varying entities and to support generative models. Also, combining
both CNNs and RNNs can recognize time varying visual entities, such as action and gesture, and to support image captioning. However, the computational requirements in CNNs are quite different from those of RNNs. The paper shows
a computation and weight-size analysis of convolution layers (CLs), fullyconnected layers (FCLs) and RNN-LSTM layers (RLs). While CLs require a massive amount of computation with a relatively small number of filter weights, FCLs and RLs require a relatively small amount of computation with a huge number of filter weights. Therefore, when FCLs and RLs are accelerated with SoCs specialized for CLs, they suffer from high memory transaction costs, low PE utilization, and a mismatch of the computational patterns. Conversely, when CLs are accelerated with FCL- and RL-dedicated SoCs, they cannot exploit reusability and achieve required throughput. So far, works have considered acceleration of CLs, or FCLs and RLs. However, there has been no work on a combined CNN-RNN processor. In addition, a highly reconfigurable CNN-RNN
processor with high energy-efficiency is desirable to support general-purpose deep neural networks (DNNs).
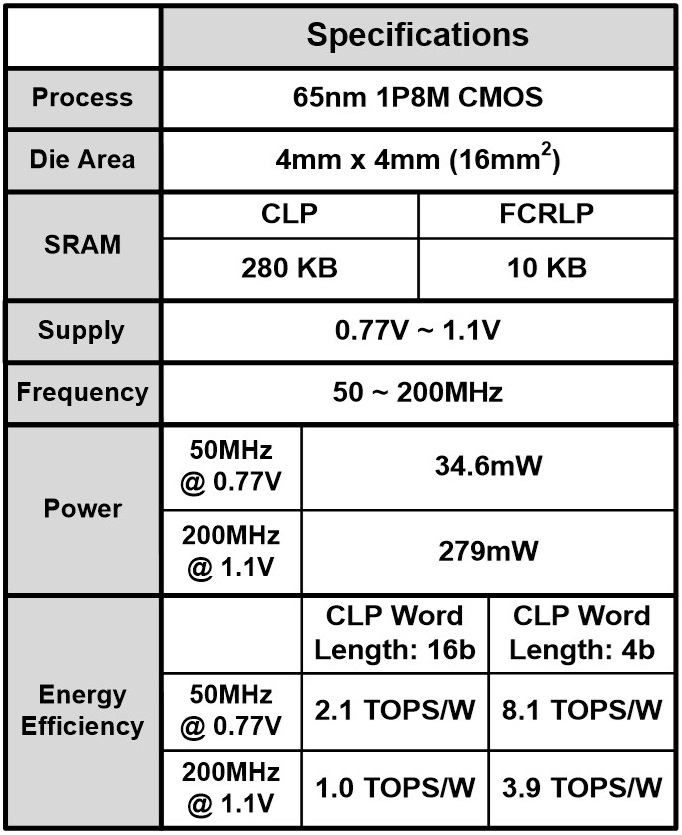
Implementation results
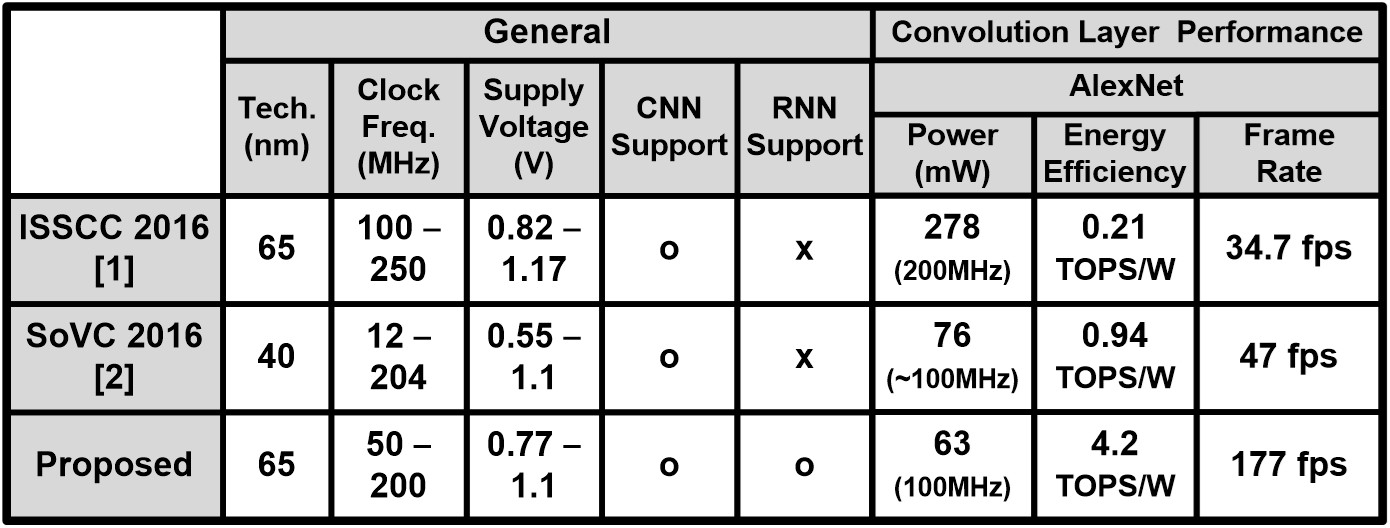
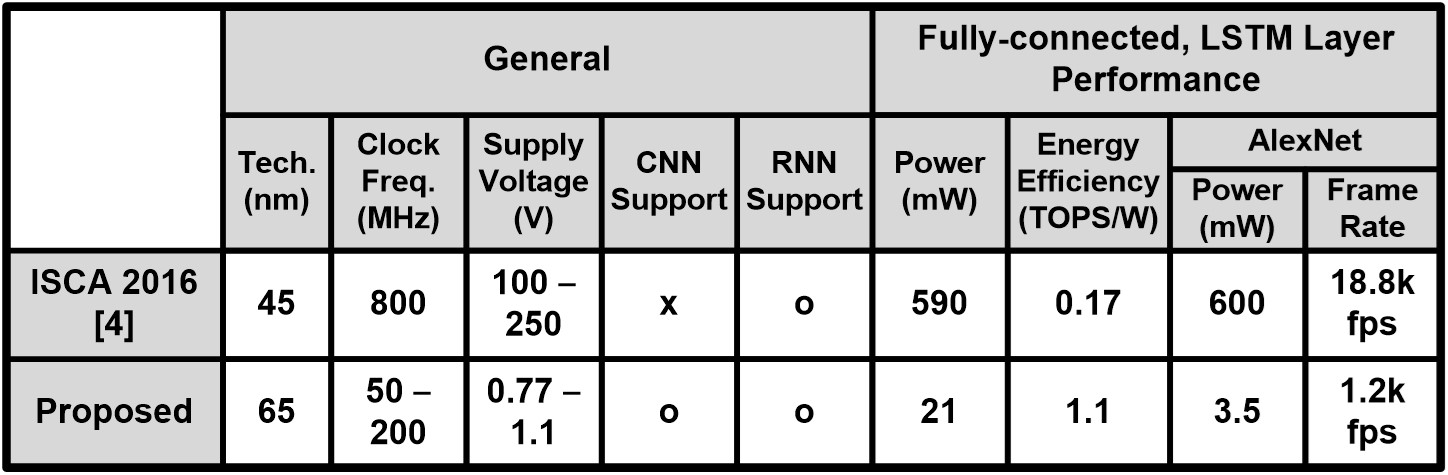
Performance comparison
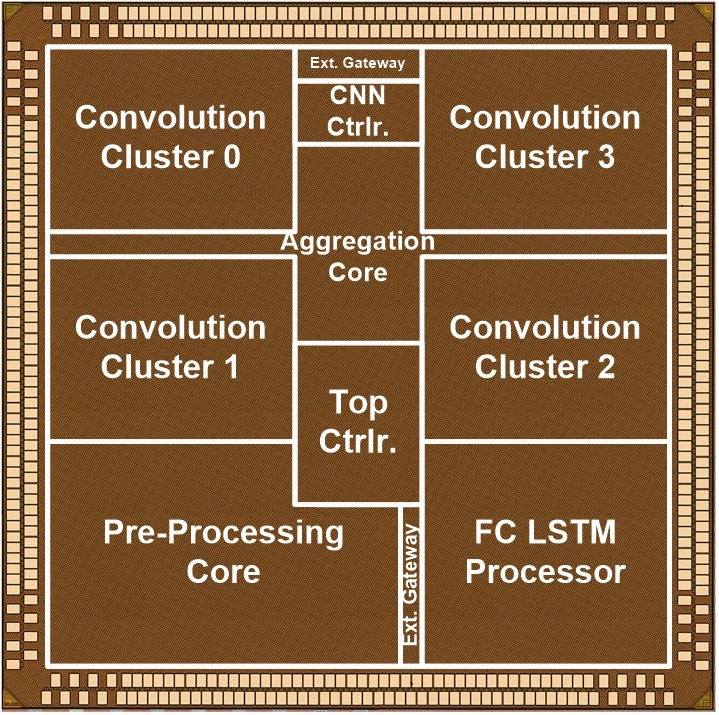
Architecture
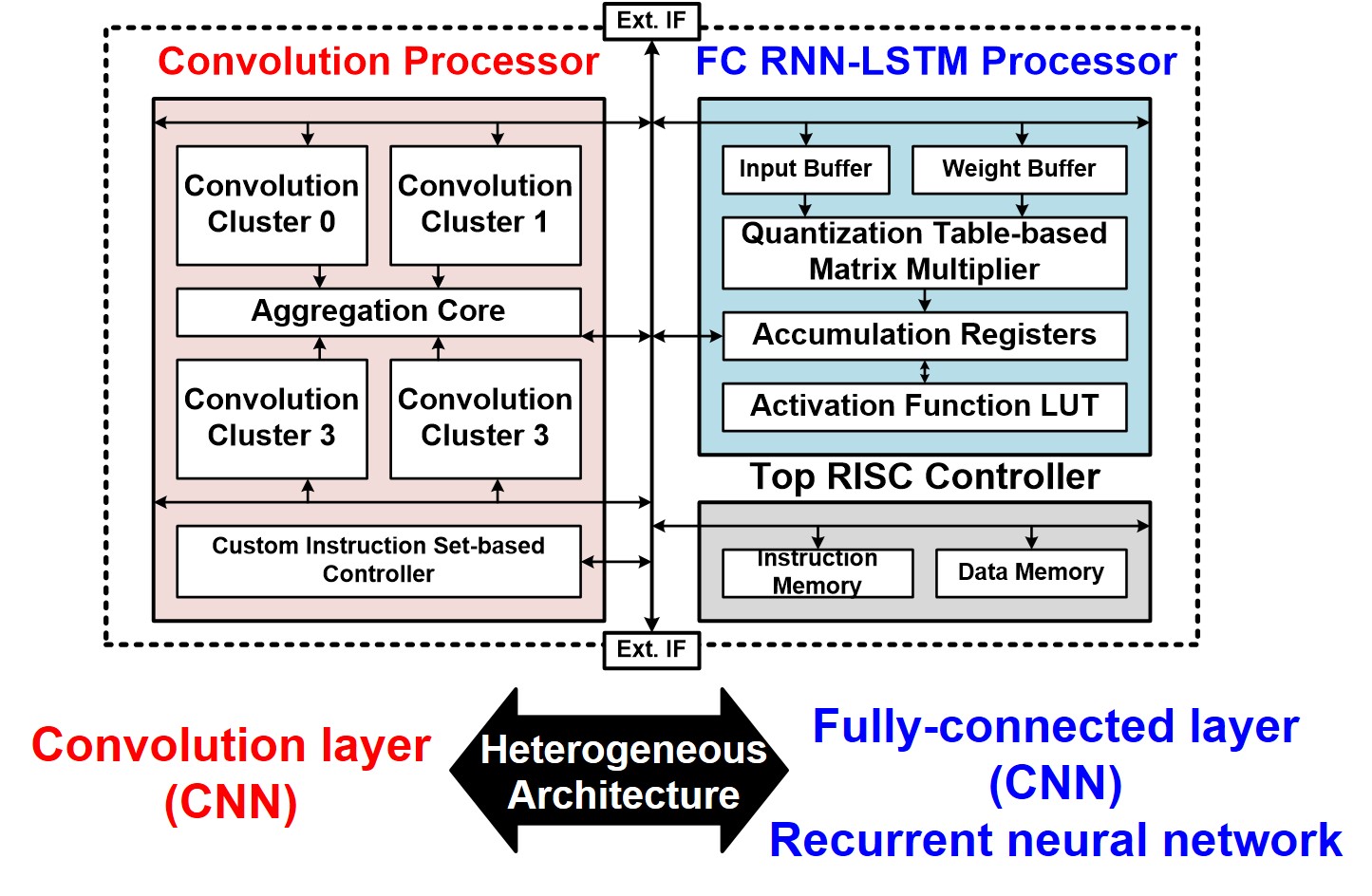
Features
- Heterogeneous Architecture
- Mixed Workload Division Method
- Dynamic Fixed-point with On-line Adaptation
- Quantization Table-based Multiplier
Related Papers
- ISSCC 2017 [pdf]
